


Authored by: Maxwell Elliott and Connor Wybranowski
Have you ever worked in a section of a codebase that is slow to build, has no ownership, no tests, and is edited constantly? If so, you have experienced a monolith. Monoliths are frustrating for developers, and they can have a profound effect on your organization; they slow down your team and your ability to drive important changes in your codebase. This was more than a hypothetical at Tinder. It was a serious challenge, and one that our team ultimately decided to address. The monolith at the core of the Tinder iOS application threatened our organization’s agility and productivity, hindering our ability to innovate and adapt quickly.
Most teams likely don’t set out to create monoliths. However, years of convenience and inertia all but guarantee that a large group of entangled code becomes even larger and more entangled without sufficient counterforces. If we consider iOS applications more specifically, the manifestation of monoliths is easier to understand given the nature of the end product. Unlike distributed applications, iOS applications are ultimately a single artifact, which means that everything in the build graph is directly or indirectly related to each other. Thus, this monolithic end product doesn’t inherently discourage the existence of a monolithic codebase that produces it.
Minimizing the critical path
In build engineering, there is a concept called the critical path which describes the longest path of dependent activities to finish a given process. In terms of compiling an iOS application, the critical path represents the summation of compilation time across all dependent targets that compose the application. To decrease the critical path time, we must make the build more concurrent; in practice, this means “flattening” the build graph so that more actions can be performed in parallel across the various cores of the build machine. By contrast, a “deep” build graph does not take full advantage of concurrency and is therefore less performant.
To illustrate this concept further, consider the following deep build graph:

Given that the iOS Application depends on Module C, which depends on Module B, and so forth, there is very little opportunity for concurrency. Therefore, the critical path will be very long: A → B → C → App
Now consider the following change to the codebase:

Since modules B and C are now “flattened” into a single layer without an interdependency, they can be compiled concurrently. Therefore, the new critical path will be shorter: A → [B, C] → App
Monolith, meet modularization
Taming monoliths is daunting and requires a concrete strategy. Our strategy of choice is called modularization, which is the process of breaking something large into smaller, composable parts. In the context of a Swift codebase, this means moving code from the monolith target (the iOS application library itself) into sub-targets (Swift modules).
Modularization exposes the contracts between code by breaking convenient access to types due to proximity. By simply forcing types to cross a module boundary, we can mitigate the use of suboptimal patterns that propagate the monolith (e.g. singletons, cyclical type references, etc.). Perhaps the most critical feature of modularization is that the compiler can check our work; once the build succeeds, the hard part is done.
Modularizing code has other significant benefits beyond exposing code contracts. Teams can colocate related code in tightly-scoped domains, which unlocks more accurate ownership opportunities. Additionally, it improves overall build times since more code can be compiled in parallel (assuming the modularized build graph is relatively flat). Further, as the amount of code in the monolith target itself decreases, monolith build times will also decrease.
After identifying a sound strategy for managing the monolith, we have to determine how to implement modularization. There are many techniques that can be used to modularize code, and each comes with unique tradeoffs that may (dis)qualify their use on your codebase. We found scale and consistency to be the primary attributes we wanted to solve for; with over 1000 files containing more than 150,000 lines of code, we knew our monolith could not be modularized consistently by hand on any reasonable timeline. Despite this, however, there were initial attempts to pull apart the monolith using more manual workflows. As illustrated below, these attempts fell victim to something we referred to as the “Sweater analogy,” where pulling the wrong thread of the monolithic sweater has the potential to unravel the entire sweater at once.
Pulling apart the sweater
To illustrate this point, let’s assume your monolith contains the following 10 files.

To start, let’s say you choose file 2 to remove from the monolith. After removing file 2, you find out via build errors that declarations in file 2 are referenced in file 8 and file 2 has references to file 9.

You remove files 2, 8, and 9 and perform another build only to find out that files 1 and 3 depend on declarations in files 8 and 9. This means that these files will have to be removed now as well.

After removing files 1 and 3, you have removed half of the files in the first pull request of decomposing your monolith. In our experience, this breadth required at least half of our 50 iOS engineers to approve the pull request while also keeping it in sync with main in our most edited target. We found that this style of decomposing our monolith would have taken at least twelve years with the cadence of reviews and rebases required. Instead, we need to find a way to remove the files with the fewest number of dependencies first.
Let’s assume you were given the relationships between all the files in the monolith up front, shown below:

The first set of files we would remove is the set of files that are leafs (nodes that have an in-degree of 0). In this monolith, that would be files 3, 4, and 10. These three files can be moved out together in a single pull request.

Then, the next pull request could remove files 1, 7, and 8.

Then, the next pull request would remove files 2 and 5.

Finally, we can remove files 6 and 9 in the last pull request to fully decompose the monolith target.

Each of these pull requests are much easier for teams to review, rebase with a changing main branch and ultimately merge into the codebase. On the surface it may seem that simply extracting files from a monolith will be the hardest part, but in retrospect rebases and code review took the majority of the time.
How can we discover the relationship between the files in a monolith?
The compiler is critical to validating the compilation correctness of this work; if the codebase builds after the edits, then the compile-time plumbing is correct. This is virtuous as it implies that the compiler knows the exact relationship between all code in the project, meaning that not only can the compiler validate that the answer is correct, it can actually give us the answer. This is obvious in retrospect, but this realization alone guided the primary strategy powering our monolith’s decomposition.
All source code uses declarations and references to define relationships. These relationships occur in a single file, across many files of a target and even across the target graph. Below is a diagram of how the Swift compiler defines these relationships.

In this workflow, build errors are introduced when the compiler is unable to resolve a reference to its declaration since that declaration has been moved out of the target. If we think like the compiler does, we can see that the mapping between the files declarations and references is critical in planning work to compile the target. Using this mapping of declarations to references, we are able to generate a directed graph of all files (nodes) and their references (edges) to other files (nodes). In practice, we generated the following graph of our monolith.
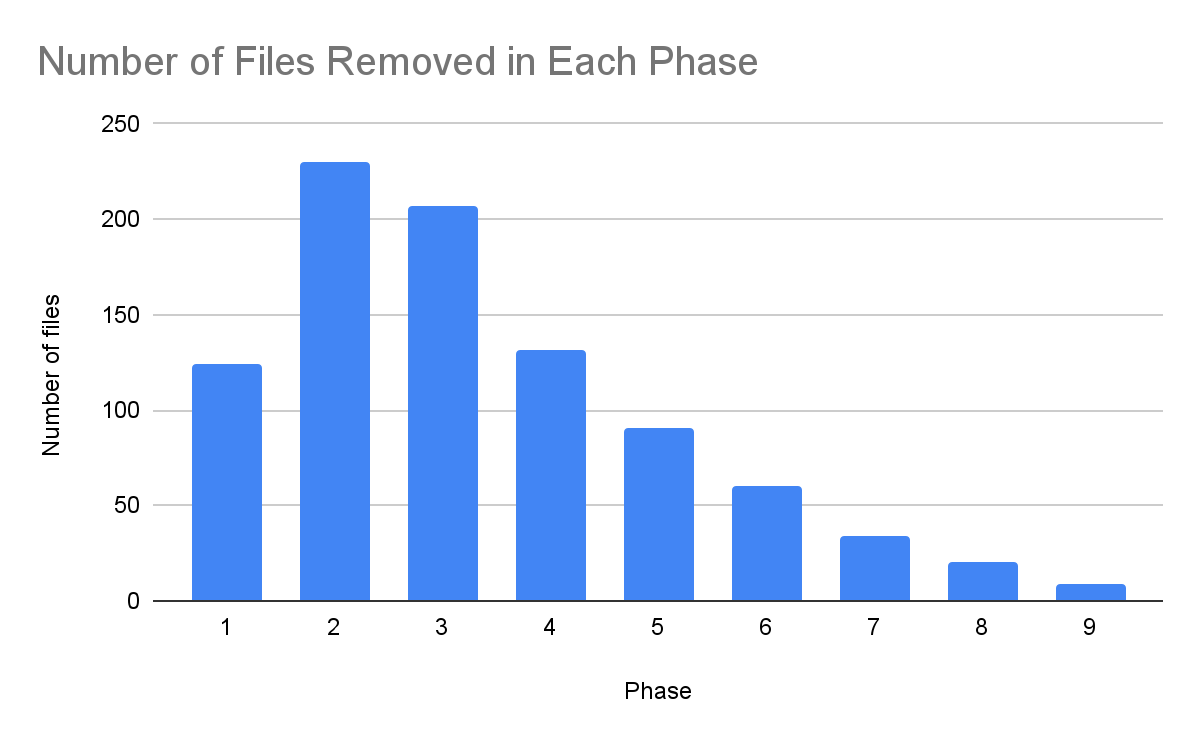
Using the same pattern as outlined above we removed the leaf nodes (nodes with in-degree of 0) in sequential phases. Many phases removed hundreds of files at a time, but file count dropped off significantly with each additional phase after phase 3. By the end of phase 4, more than 50% of the work was already done.
Moving files is the first step, but ultimately the code still needs to compile successfully. After fixing thousands of compilation errors due to file moves, here is what we found to be true:
- Each file moved required edits to 15 additional files on average
- The universe of required edits is not very large — the following edits were the most common in our Swift codebase:— Dependencies: Update Swift module dependencies in the subtarget (extraction destination) and the monolith
— Imports: Update imports in remaining monolith files that referenced declarations in now-extracted files
— ACL: Expose declarations to the monolith by updating Access Control Levels (ACL)
— DI: Satisfy dependency injection (DI) - At a certain scale, this work is almost impossible to be performed consistently and correctly by hand — the earlier you find automations for this the better
Insights
Having attempted decomposition with and without automation, we found the following formulas to accurately describe the effort required to complete a single phase in both cases:

To put the differences between these formulas into perspective, the automation allowed our monolith to be fully decomposed in under 6 months. Without automation, however, we estimated that this same work would have taken us nearly 12 years to complete. The largest contributing factor to this immense jump in time is the sheer number of builds required to surface and validate compilation error resolution. Importantly, the automation converts quadratic effort into something closer to a constant.

Considering the formulas we shared above, we found our distribution of total time spent on the decomposition effort to be the following:

Importantly, automation not only performed the otherwise manual labor of extracting the files, but it also made rebase-related conflicts a non-issue; we could simply re-run the automation to “heal” any issues surfaced by conflicting changes. Code review was the only component that our automation could not solve for, and as such it represented the vast majority of time spent on any given phase.
Conclusion
We extracted over 1000 files from our monolith without a single P0 incident in under 6 months. To put that into perspective, it took 10 years for those 1000 files to be added to the monolith. This work reduced our monolith build time by 78% and changed the trajectory of the codebase because the remaining code is no longer seen as a place to hide from rising standards in the rest of the codebase. Moreover, we secured these wins by disallowing the addition of files to the monolith, making it clear to teams that active feature development should not take place in this target.
Upon reflection, we realized that this effort could have been ignored for years to come; teams did not universally view the monolith as a direct threat to their productivity or the greater organization. However, the data demonstrated otherwise. Using a structured approach allowed us to solve a class of issues that was large, and deemed unsolvable by many ICs. By completing this work we have dismantled myths surrounding other issues of this class and raised the bar on future projects. Moreover, by shining a light on the darkest parts of our codebase, we demonstrated that the most challenging technical efforts are within reach.


