

How Tinder® Uses AI to Rank Profile Photos




Introduction: Why Photo Ranking Matters
Choosing the right photos isn’t as simple as a bright smile or a curated background. Great pictures from great memories with friends, on a trip, or doing something you love might seem like solid choices, but what a user likes best isn’t always what performs well.
That’s the problem Smart Photos was designed to solve. Instead of asking users to guess which photo, Smart Photos automatically orders profile photos based on how they resonate with other members on Tinder®, while still giving users full control with the ability to opt out or manually order their photos at any time.
Our latest Smart Photos system is the next step in that evolution. It uses a Vision‑Language Model (VLM) to better understand modern dating photos in context, helping us rank an entire set of photos more effectively and helps users receive more likes, form more matches, and start more conversations.
In this post, we’ll walk through this new VLM‑based photo ranking system, how it works under the hood, and what we learned along the way.
Motivation: Why Vision‑Language Models?
Before moving to Vision‑Language Models, Smart Photos relied on deep learning models based on convolutional neural networks (CNNs) to rank profile photos. This approach worked well for learning visual signals directly from images and delivered strong gains.
CNNs excel at detecting patterns like composition, lighting, and clarity, but they struggle to capture higher‑level context. In an environment like Tinder, this distinction matters. The task isn’t just detecting faces or lighting quality It’s understanding circumstance , vibe, humor, and subtle social cues that shapes perceived aesthetics.
Vision‑Language Models combine a vision encoder trained on the internet‑scale image–text data with a large language model capable of higher‑level reasoning. Large language models are trained on vast amounts of text and multimodal data, which gives them a strong grasp of the language, social norms, and common patterns people use to describe the world. When paired with a vision encoder, this allows the system to ground visual signals in richer semantic representations, enabling more nuanced reasoning about what an image conveys beyond its raw pixels. Together, these components allow the system to connect what’s visible in an image with broader semantics learned from language. As a result, the model moves beyond low‑level visual signals and understands photos in a way that’s closer to how people perceive them, considering not just what’s in a photo, but what it conveys.
Model Architecture and Training:
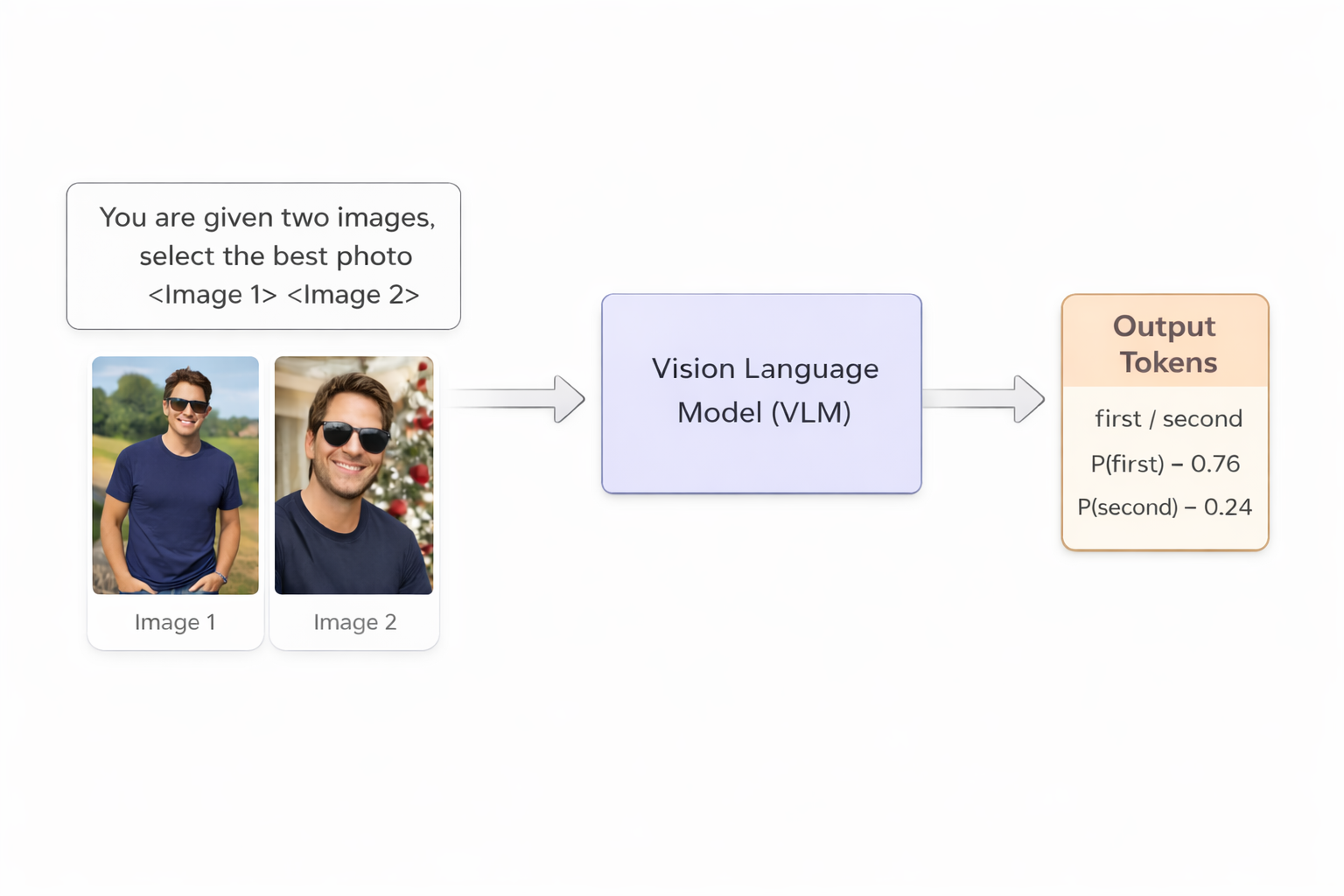
Our VLM based system reframes photo ranking as a pairwise comparison problem.
Instead of asking, “Is this photo good?”, we ask a more natural question:
Given two photos of the same person, which one is more likely to perform better as a profile photo?
This mirrors how humans make judgments: comparatively, not in isolation, and with the full context of a profile in mind.
At a model level:
- Input: Two images + a short prompt (optionally augmented with basic profile context such as age, gender, target gender, and country) asking the model to select the better photo
- Output: Token probabilities for first vs. second
- Training objective: Supervised fine‑tuning (SFT) on the label token only
For a user with N photos, we run all N choose 2 comparisons. We then aggregate the results:
- Win count: How often a photo wins against others
- Average score: Mean probability across all pairwise comparisons
Sorting by these signals produces the final ranking.
We use an Opensource Vision Language model trained using LoRA to balance performance with inferencing efficiency.
Training Data: Learning from Real Outcomes
To train this system, we used interaction data collected using a Multi‑Armed Bandit (MAB) methodology. In this setup, different photos of a user are shown on the top position over time. This gave us per‑photo performance signals (likes and impressions) when photos appeared in the top position.
Compared to purely random exposure, this approach allocates more impressions to harder or high‑variance photos, which becomes especially important when engagement signals like likes can be sparse.
From this data, we generated pairwise training examples:
- Each example consists of two photos from the same user
- The label indicates which photo performed better with statistical significance
We intentionally filtered for high‑confidence pairs to reduce noise and ensure the model learned meaningful distinctions.
Evaluation: Does It Actually Work?
Offline, the VLM‑based system showed a significant lift over our previous deep‑learning model:
- Pairwise accuracy: ~76% (up from ~68%)
- ROC‑AUC: ~0.84
With offline simulation of full‑profile rankings, we saw consistent gains in overall ranking quality across all profile sizes. As a proxy metric, we measured improvements in top‑photo accuracy:
- +7–10 percentage points improvement depending on the number of photos
This means more users are seeing a better‑ordered photo set overall, with stronger photos surfaced earlier in the profile, exactly what Smart Photos is meant to do.
We validated these offline gains with online A/B experiments, where the new ranking system was compared against the existing approach in production. In these tests, we observed consistent downstream improvements across the ecosystem, including users receiving more likes, forming more matches, and engaging in more conversations, reinforcing that better photo ranking translates to better real‑world outcomes.
Model Experiments and Learnings
Building a production‑ready VLM for photo ranking required exploring a wide range of modeling, training, and data decisions. Here are the most impactful experiments and what we learned from each.
Impact of LoRA Configuration
We experimented with LoRA ranks ranging from 8 to 64 to balance model expressiveness with inference efficiency. We observed that a LoRA rank of 32 delivered the best overall results. Increasing the rank beyond 32 led to diminishing returns and, in some cases, a drop in pairwise accuracy despite higher computational overhead.
Impact of Batch Size and Epochs
We varied batch sizes and training duration to study convergence behavior, particularly given the noisy nature of engagement-based labels.
- We observed strong performance variance across batch sizes, with larger effective batch sizes leading to more stable optimization and better overall performance.
- Experiments with batch sizes ranging from 16 to 128 showed consistent improvements as batch size increased.
- Most performance gains were achieved within the first epoch, with diminishing returns from longer training runs.
Impact of Input Image Resolution
We evaluated training and inference using image heights ranging from 128 to 800 pixels to understand the trade‑offs between visual fidelity and system cost.
- As image resolution increased, the model was able to pick up finer visual cues, and we also observed qualitatively stronger performance on cases with larger technical quality differences, especially where image clarity and sharpness played a key role, leading to improvements in pairwise accuracy.
- At the same time, higher resolutions increased training time and serving cost, making it important to balance quality gains against inferencing costs
Impact of Training the Vision Encoder
We systematically evaluated freezing and training different model components to understand how each part of the model contributed to performance.
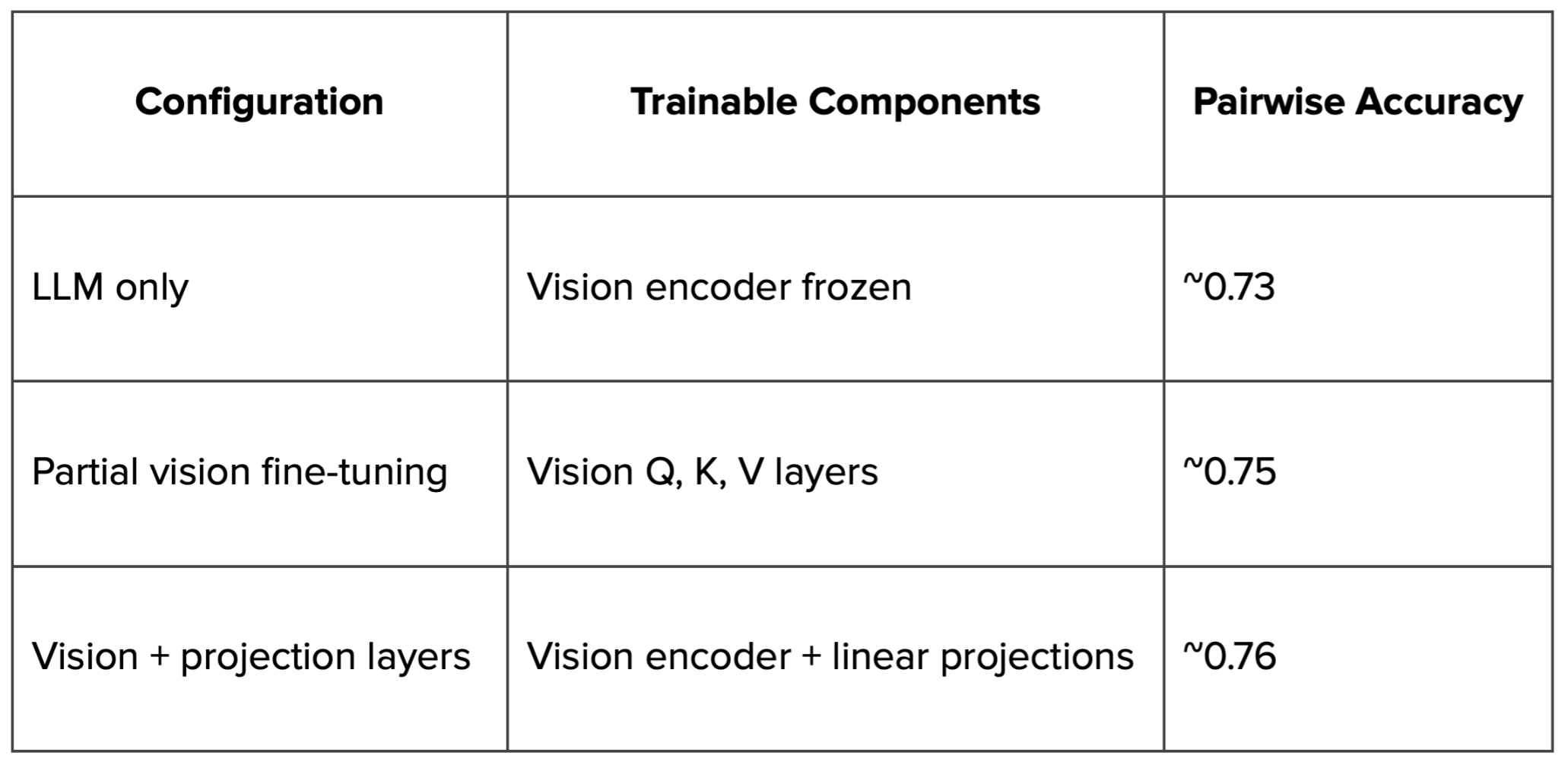
We observed that training the vision encoder led to the most significant performance gains.
Impact of Adding Profile Features to the Prompt
We evaluated how adding profile context to the prompt affected ranking performance, focusing on signals such as target gender, age, relationship intent, and country.
Overall Impact
- Adding profile features led to a ~0.2 percentage point improvement in pairwise accuracy.
- Combining profile features with 2× more training data increased the lift to ~0.8 percentage points, indicating that contextual signals benefit more from additional data.
Biggest observed lifts from adding profile context:
We saw the strongest gains in cohorts where contextual signals helped disambiguate how photos should be interpreted.
- Target gender: Men looking for men saw one of the largest lifts, with pairwise accuracy improving by ~1.8 percentage points.
- Age and relationship intent: Younger and mid‑age users, as well as users with explicitly stated relationship intent, consistently saw lifts in the ~1–1.3 percentage point range.
- Geography: Markets with sufficient data, such as the U.S. and Brazil, benefited more reliably from added context, while low‑data regions showed higher variance.
Impact of Data Quality
This task inherently involves noisy labels, as training data was derived from real-world engagement signals using the MAB process.
While the MAB setup helped surface informative comparisons, engagement signals such as likes can be sparse and influenced by many factors beyond the photo itself, including user preferences, timing, and other profile attributes. As a result, a like was only a weak proxy for photo quality, and not every interaction could be cleanly attributed to the image being shown.
In practice, this meant that training on high-confidence, statistically significant photo pairs consistently outperformed training on larger but noisier datasets, reinforcing the importance of prioritizing cleaner labels over raw data volume for subjective ranking problems driven by implicit feedback.
Scaling Laws: Model and Data Growth
We explored how performance scaled across three key dimensions: model capacity, training data volume, and contextual signals.
- Model capacity: Smaller models (≤3B parameters) struggled to converge reliably and had difficulty capturing nuanced aesthetic and social signals. In contrast, larger models (7B parameters) showed more stable training dynamics and were better able to model subjective, context‑heavy ranking decisions.
- Training data volume: Increasing the amount of training data led to better convergence and more stable learning, particularly for harder and more ambiguous photo pairs.
- Model–data interaction: Larger models were able to take advantage of additional data more effectively, showing continued improvements rather than early saturation.
Taken together, these results suggested there is still meaningful headroom from scaling model size and data volume in tandem, with clear opportunities for future gains as larger models and richer datasets become available.
Serving:
Serving a large VLM in production came with its own set of challenges, from latency and cost constraints to the need for frequent iteration and scaling reliably to millions of requests.
To support this, we used an in‑house managed LLM‑serving platform built on top of a high‑throughput LLM inference engine. This allowed us to efficiently serve large models by leveraging features such as continuous batching, optimized memory management, efficient KV‑cache, quantization and high GPU utilization, all of which helped reduce latency and improved throughput at scale.
What We’re Building Toward
At its core, this project was about using AI in a meaningful way to help people get more value from their Tinder experience. By better understanding photos in context and ranking them more effectively, we aim to reduce guesswork for users, put their best selves forward, and ultimately help them find what they’re looking for.
This work is one of many in-house efforts to make the Tinder experience feel more tailored by becoming more personalized. By combining large-scale data with modern VLMs, we’re building systems that translate into real improvements for users, helping them find the people and interactions they’re looking for. We know every user is different, and by tailoring how profiles are presented, we can help reflect and amplify that individuality.
As we continue to iterate, our focus remains the same: applying AI thoughtfully and responsibly to create more meaningful connections for people on our platform.
At Tinder, we’re building the future of meaningful connections. Join us.
Contributions
This work was made possible by a collaborative effort across multiple teams at Tinder.
Product: @Aaron.Silvers-Lamas @Molly.Chisholm @Alex.Levich
Data Science: @Kevin.Celustka
Infrastructure: @Ankush.Ransiwal @Alfred.Lee
Backend: @Gabriela.Rodriguez-Florido @Xincen.Hao @Jason.Chang


